
success story

Fragile OSINT architecture burning 94% of the infrastructure budget

Type
Legacy Rescue & Modernization
Year
2022 - Ongoing
success story
Legacy Rescue & Modernization
2022 - Ongoing
An international client creating services and technologies in the Finance sector contacted us to evaluate the critical issues of an OSINT SaaS product inherited from a previous acquisition. The system had grown disorderly, resulting in high infrastructure costs, low reliability, maintenance difficulties, and a deteriorating time-to-market.
We had already successfully collaborated with the client in the past; this accelerated the project kickoff and allowed for an incremental journey: stabilization of the existing system, gradual redesign, and an evolutionary/maintenance phase that is still active.
The engagement involved an initial assessment phase—our Technical Due Diligence—followed by a second phase of incremental redesign, and a third evolutionary and maintenance phase, which is currently ongoing.
The request was clear: get a platform back on track that was born with an excellent service intuition but had become, over time, a fragile and expensive system to manage.
At the time of engagement, the platform contained approximately 50 billion records, totaling 12.5 TB. However, the system was unreliable, costly to maintain, and increasingly difficult to evolve.
The infrastructure had grown haphazardly, with a direct impact on costs, maintenance, and scalability.
In this scenario, our Technical Due Diligence was decisive. We analyzed the infrastructure, codebase, configurations, and end-to-end data flows (ingestion → normalization → indexing → search → watchlist). The resulting map of critical issues included:
Excessively complex and redundant architecture, with fragmented logic across numerous components and modules, and a high number of operational failure modes;
Technology choices inconsistent with NFR (Non-Functional Requirements) goals, often driven by tool popularity rather than functional suitability – including the use of ElasticSearch as the primary database for flows requiring immediate consistency;
Lack of deduplication mechanisms and protection against abuse (rate limiting), negatively impacting performance and sustainability;
Fragmented technology ecosystem, including improper dependencies on temporary states (e.g., transient coordination and metadata handled fragility), incomplete process supervision, and non-homogeneous observability;
Disproportionate infrastructure costs compared to the value generated.
In parallel, we formalized the domain constraints: datasets on the order of tens/hundreds of billions of documents with significant monthly growth; real-time exact-match queries on a single field; the need to create new indexes with minimal service impact; "spiky" search loads; and a watchlist system that saves and notifies new matches.
Rapid and targeted interventions, to ensure operational continuity and reduce friction in daily activities;
Medium-to-long term roadmap, to gradually replace critical components with simpler, more robust, and cost-effective solutions, reducing complexity and costs;
Technical spikes and proof-of-concepts, regularly discussed with the client to validate assumptions (query times, reindex times, update and query costs) and guide architectural decisions with measurable data.
In the complex context we inherited, our goal was twofold: to radically simplify the architecture while guaranteeing performance, reliability, and scalability. We therefore adopted a “mechanical sympathy” approach: reducing components and dependencies, leveraging managed cloud primitives, and building linear, measurable, and easily optimizable data paths.
We built an indexing and search engine based on a simple principle: dividing the dataset into deterministic partitions on AWS S3 so that every query becomes a targeted access to a small, predictable portion of the data.
Indexed data is organized into autonomous partitions on object storage, built with hash-based (hash-prefix) logic.
During the query phase, the system calculates the partitioning key and retrieves only the relevant partition, completing the selection with an in-memory filter for the exact-match.
The structure allows for independent index creation or regeneration, reducing service impact and simplifying reindexing activities.
This choice enables stable lookup times, natural scalability via on-demand compute, and stricter cost control compared to approaches based on always-on components.
We restructured the ingestion flows, making them linear and observable, standardizing formats and transformation rules throughout the process (ingestion → normalization → master → indexing).
Definition of consistent and versionable schemas to reduce ambiguity and regressions.
Use of targeted compression algorithms to improve storage efficiency and throughput while maintaining high read performance.
Native support for full reindexing and incremental updates to avoid massive rewrites and reduce update cycle time and costs.
Wherever possible, we shifted the operational load to managed AWS services, reducing systemic complexity and points of failure.
AWS S3 as durable and scalable storage for master copies and indexes.
On-demand compute for queries and search functions, particularly effective for bursty loads.
Managed queues and containerized jobs to decouple ingestion and indexing, introducing controllable backpressure and parallelization.
We introduced a governance layer to make the platform more robust and sustainable over time:
Access control and throttling per endpoint/tenant, limiting improper use and stabilizing latency.
Accounting and tracking of main operations to support reporting, cost allocation, and capacity planning.
Finally, we made the entire system more “operable” in a structural way:
Structured logging and metrics on key steps (ingestion lag, indexing times, error rates, query latency).
Identification and removal of the most impactful bottlenecks through a continuous cycle of measurement and optimization.
The intervention produced measurable results both technically and economically:
AWS infrastructure costs reduced by approximately 94%, with monthly costs dropping from ~$34,000 to ~$2,000 for the same volumes (about 17× reduction);
Proven scalability: the ingestion pipeline sustained a continuous increase in volume, growing in one year from ~50 billion records (12.5 TB) to ~250 billion records (62 TB);
Improved time-to-market: an architecture that is easier to extend allowed for faster integrations with third-party services and new features, reducing the risk of regressions and deployment complexity;
Superior operability: fewer points of failure, better observability, and faster diagnosis.
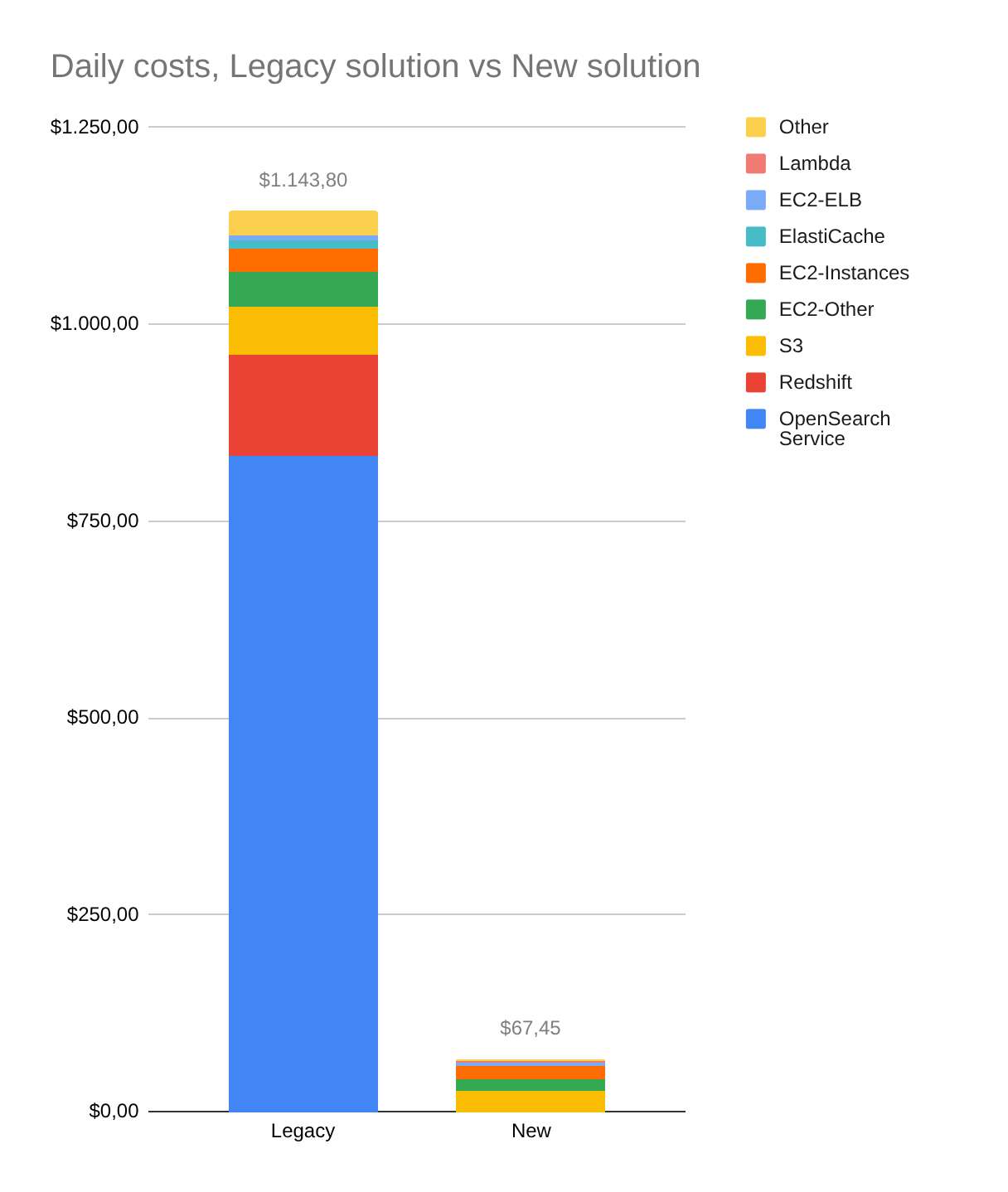
-93%
operational costs
+400%
managed data volume
1 year
(with active maintenance phase)Thanks to the new architecture, the client can now rely on a lean, sustainable OSINT SaaS platform that is growing once again: a solid technical foundation, designed to scale with massive datasets while keeping cloud spending under control.
Beyond the technical aspects, the project delivered these results thanks to a relationship of mutual trust and a pragmatic working method: rigorous assessment, POC-validated choices, incremental migration, and constant alignment with business constraints (costs, maintainability, evolvability).